GPT-Image-1.5 is available on HummingBytes for users who specifically want OpenAI image workflows like transparent PNG output, multi-image compositing, structured infographics, UI mockups, and geometry-sensitive transformations.
Supports transparent RGBA-style product cutouts for catalog workflows
Supports multi-image compositing, virtual try-on tests, and structured layout tasks
Best treated as a specialist workflow option rather than an all-purpose default
Most users should start with Nano Banana 2. This page is for users who specifically want GPT-Image-1.5 for transparent output, compositing, or structured layout workflows.
Example tasks
What GPT-Image-1.5 currently supports on HummingBytes
These examples show the kinds of structured workflows users may still want to test with GPT-Image-1.5 inside HummingBytes.
Model input
Garment input
Final try-on
Virtual try-onGenerated with GPT-Image-1.5
Flat-lay garment applied to an existing model photo
This is aimed at fashion and ecommerce teams that want to reuse approved model photography while swapping in new garments without booking another shoot.
Prompt direction
Keep the original background, framing, face, and pose. Apply the uploaded yellow floral dress naturally to the model with believable draping and lighting.
InputGPT-Image-1.5 result
Transparent PNGGenerated with GPT-Image-1.5
Catalog-ready product extraction with clean edges
This is one of the clearest workflow savings on the page: isolate a product cleanly, preserve the geometry and label, and hand a transparent asset directly into the catalog pipeline.
Prompt direction
Extract the skincare bottle onto a transparent RGBA background with crisp edges, preserved label legibility, and a polished product finish.
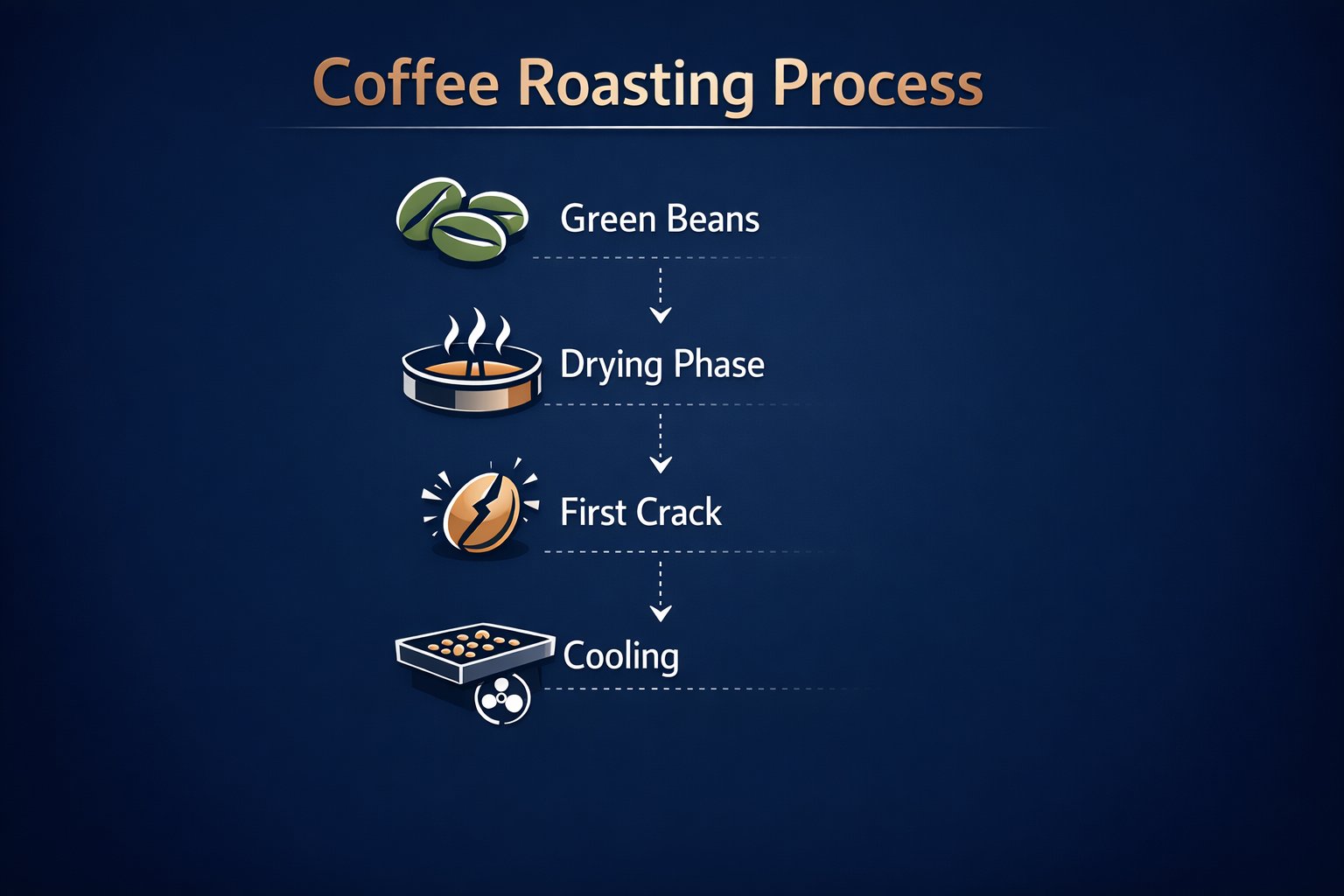
InfographicGenerated with GPT-Image-1.5
Structured business design with exact spelled labels
This is the kind of output consultants, marketers, and in-house design teams pay for when they need readable, presentation-ready diagrams instead of generative art.
Prompt direction
Build a modern navy presentation slide explaining the coffee roasting process with four exact stage labels and clean visual hierarchy.
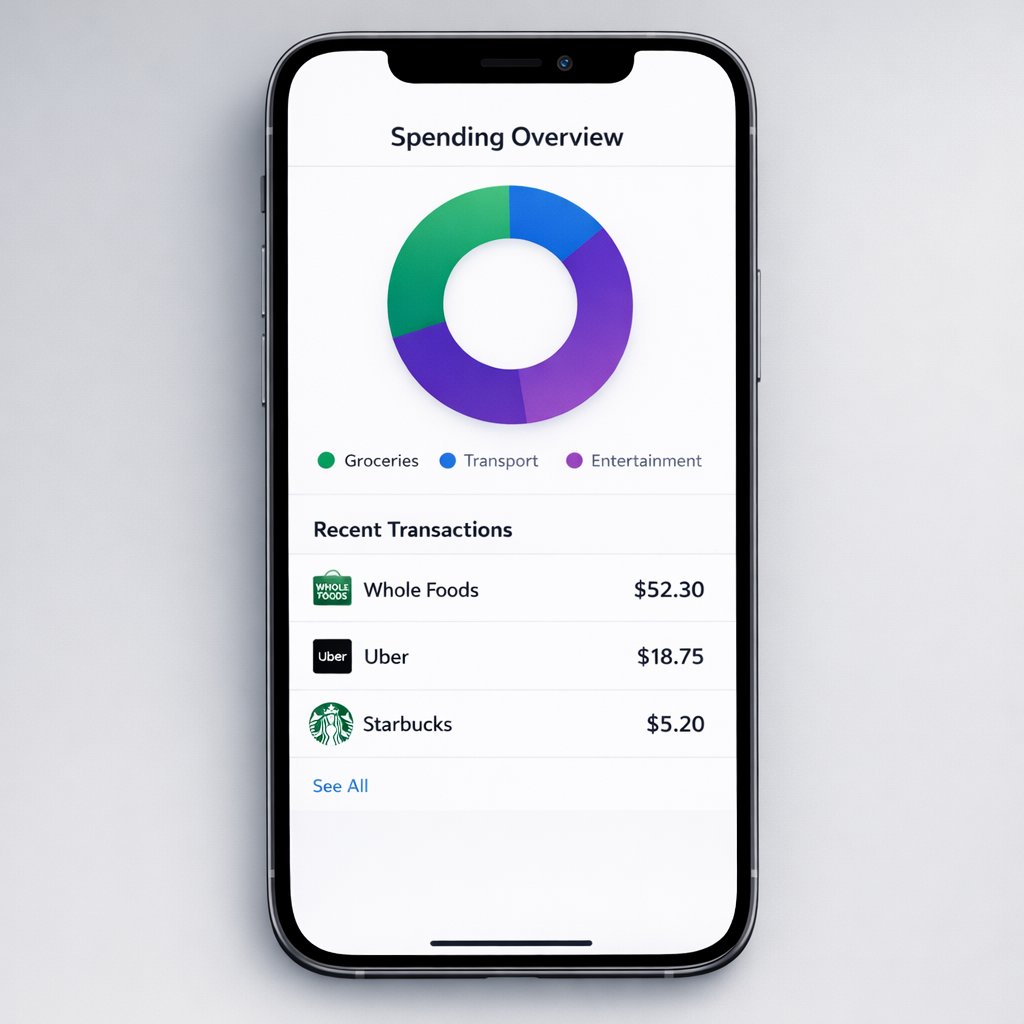
Product UIGenerated with GPT-Image-1.5
Shipped-looking mobile finance interface mockup
This is where interface hierarchy matters: spacing, cards, typography, and believable app structure instead of fuzzy concept art.
Prompt direction
Create a polished personal finance dashboard inside a bezel-less smartphone with a donut chart and three exact merchant rows.
InputGPT-Image-1.5 result
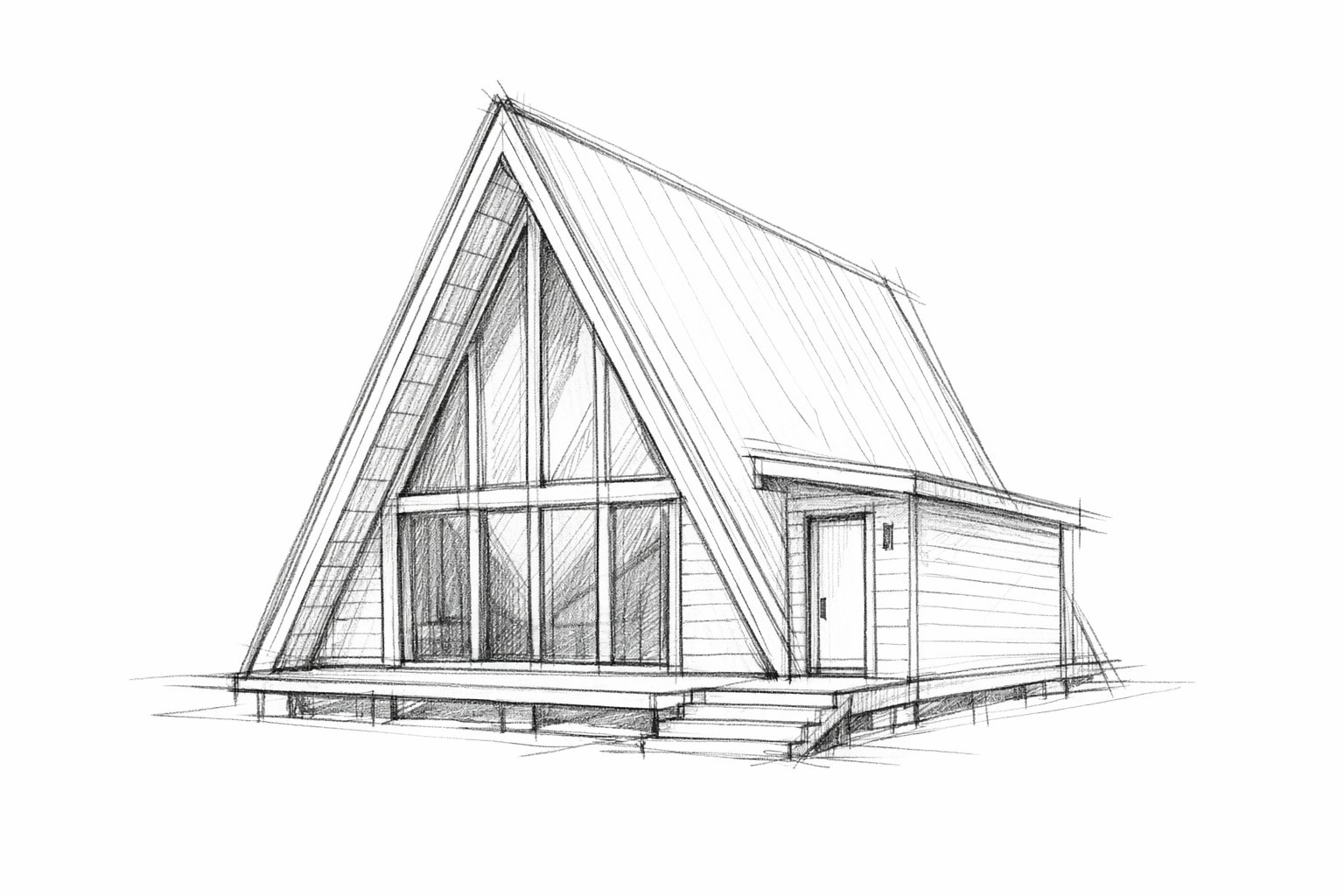
Sketch to renderGenerated with GPT-Image-1.5
Architectural presentation render that keeps the original geometry
This is designed for teams that start with a strict structural input and want the model to add materials, lighting, and realism without inventing a different building.
Prompt direction
Turn an uploaded A-frame cabin sketch into a photoreal render while preserving the exact layout, perspective, and opening positions.
Where it may help
Where GPT-Image-1.5 may still be useful
GPT-Image-1.5 works best when the workflow has structure: a reference image, a layout to follow, or a specific production constraint like transparent output. These are the narrower cases where it makes sense to test.
Catalog cleanup workflows
Try it when the real need is transparent output, clean cutouts, and product-prep steps that are awkward to do manually at scale.
Virtual try-on experiments
Useful when you want to test whether a garment-application workflow can work with your existing model photography and product references.
Infographic and slide drafts
Worth testing when you need structured visual communication with readable labels and a more presentation-like layout.
UI and dashboard mockups
Still relevant for users who want to explore interface-like outputs and see how far the model gets on hierarchy and in-image text.
Geometry-led transformations
A reasonable test case when the output starts from a sketch, layout, or structured input and the model needs to keep that structure recognizable.
Users who specifically want OpenAI image output
Some users simply want GPT-Image-1.5 available as an option. This page exists to support that choice clearly and honestly.
Less ideal for
GPT-Image-1.5 is a specialist. These are the jobs where other models on HummingBytes are a better starting point.
Default image generation for most users
Not the best starting point when the goal is strong everyday image generation and editing. Nano Banana 2 is a better default for that.
High-volume everyday iteration
If the job is broad exploration, routine creative variation, or fast back-and-forth editing, this is usually not the most convincing option.
Photorealistic scenes without structural input
When the job is open-ended scene generation from a text prompt alone, without a sketch, reference, or layout to anchor the output, other models on HummingBytes tend to produce more convincing results.
What to expect
How to think about GPT-Image-1.5 on this site
Treat this section as a scope check. The right question here is not whether GPT-Image-1.5 wins the whole lineup, but whether it supports a workflow you specifically want to test.
Treat GPT-Image-1.5 as a supported specialist option for certain structured workflows, not as the default image model for most HummingBytes users.
Transparent outputs
Useful when
You want to test background removal, clean product isolation, or other catalog-style tasks where transparent output is part of the workflow.
Watch for
The result still has to earn its place through output quality; capability alone is not enough.
Structured layouts
Useful when
You want to test infographics, dashboard-style mockups, or other images where hierarchy and readable text matter more than pure aesthetics.
Watch for
Output consistency can vary, so test with your actual inputs before committing to a production workflow.
Multi-image workflows
Useful when
You want to test compositing or virtual try-on scenarios that depend on multiple inputs rather than one prompt-only image.
Watch for
Support for the workflow does not automatically make it the best model choice overall.
Why it may still be worth testing
What GPT-Image-1.5 can still save in the right workflow
The clearest savings come from narrower workflow wins - fewer manual steps, less tool-switching - rather than broad speed or cost advantages.
These savings are real but narrow. They apply when the task specifically needs transparent output, compositing, or structural fidelity, not as a general speed or cost argument.
Less manual masking
Transparent PNG output can remove a whole background-removal step from catalog prep and merchandising workflows.
Fewer design handoffs
Structured infographics and UI mockups reduce the need to move every early deliverable into Figma or Photoshop before it becomes readable.
Reuse existing photography
Virtual try-on and multi-image compositing let teams squeeze more value out of existing model and product photography instead of reshooting every variation.
Better production control
When geometry, label integrity, and hierarchy matter, this model is easier to justify than a faster option that needs cleanup afterward.
Quality dial for the job
Use lower quality for faster iteration and higher quality when the final asset needs to hold up in production or client review.
Where to go next
Model pages are most useful when they connect back into the workflow, use-case, and benchmark pages that help you act on the decision.
Start with the kind of brief this model is meant to handle
These prompts lean toward production deliverables instead of generic visual exploration, because that is where GPT-Image-1.5 should earn its keep.
Virtual try-on
Apply a garment to an existing model shot
Goal: Virtual clothing try-on for a fashion ecommerce product page. Background and scene: keep the original model photo exactly the same. Subject: the woman from the source image now wearing the uploaded yellow floral dress. Key details: match drape, folds, lighting, and body geometry naturally. Constraints: preserve her exact face, pose, hairstyle, and proportions.
Goal: Prepare a product cutout for catalog use. Background and scene: transparent RGBA PNG. Subject: the skincare bottle from the uploaded image. Key details: crisp silhouette, preserved label readability, clean edges, subtle contact shadow. Constraints: keep the product geometry exact and do not restyle the bottle.
Goal: Create a polished educational infographic. Background and scene: deep navy presentation slide. Subject: the coffee roasting process. Key details: clear stage flow, minimalist icons, and the exact labels Green Beans, Drying Phase, First Crack, and Cooling. Constraints: keep typography clean, legible, and completely free of gibberish.
Goal: Create a realistic mobile app UI mockup. Background and scene: soft gray presentation background with a modern smartphone frame. Subject: a personal finance dashboard. Key details: donut chart, white interface, and transaction rows for Whole Foods, Uber, and Starbucks. Constraints: make it feel like a real shipped iOS app, not concept art.
Goal: Turn an architectural sketch into a photoreal render. Background and scene: golden-hour pine forest setting. Subject: the A-frame cabin from the uploaded sketch. Key details: charred timber siding, reflective glass, matte black standing-seam roof. Constraints: preserve the exact layout, perspective, and structural openings from the sketch.
GPT-Image-1.5 is a supported OpenAI image model on HummingBytes for users who specifically want workflows like transparent PNG output, compositing, structured layouts, and UI-style image generation.
Does GPT-Image-1.5 support transparent backgrounds?
Yes. One of the clearest reasons to test it is transparent-background output for product extraction and catalog preparation workflows.
Is GPT-Image-1.5 good for UI mockups and infographics?
These are among the workflows this page focuses on. If your goal is interface-like layouts or structured visual communication, it is reasonable to test there.
Is GPT-Image-1.5 good for virtual try-on or multi-image compositing?
Those are supported workflows on HummingBytes and they are among the clearest reasons to test GPT-Image-1.5 specifically.
Is GPT-Image-1.5 the default image model on HummingBytes?
No. The default recommendation for most users is Nano Banana 2. This page exists for users who specifically want GPT-Image-1.5 for supported workflows. See Nano Banana 2 model page
Can I use GPT-Image-1.5 for ecommerce catalog prep?
Yes. That is still one of the clearest reasons to test it, especially when the workflow includes transparent extraction, product cleanup, or multi-image compositing.
When should I use GPT-Image-1.5 instead of Nano Banana 2?
Start with Nano Banana 2 for everyday image generation and editing. Move to GPT-Image-1.5 when you specifically need transparent PNG output, multi-image compositing, or structured layouts like infographics and UI mockups. See Nano Banana 2 model page
Ready to test it honestly?
Run GPT-Image-1.5 on one real workflow and decide from the output.
The fastest way to evaluate this model is to try it on a task where transparent output, compositing, or structured layout actually matters to you.